
After considering a range of analysis approaches, the most suitable were content and thematic analysis. However, distinguishing between the two was quite challenging. Content analysis sits under qualitative and quantitative methods. For this study I will be focused on the qualitative approach of content analysis which looks at organising codes into categories or themes.
These methods are similar in the preparation and organisation of data, focusing on code and theme creation, and are often used interchangeably (Vaismoradi 2013). However, the way in which they analyse and the present the data differs. In content analysis the relevance of a code is based on frequency, the overt content is then presented. This provides an objective approach mitigating researcher bias. However, utilising solely frequency analysis may ‘simply reflect greater willingness or ability to talk at length about the topic’ (Loffe & Yardley 2004; Shields & Twycross 2008 cited by Vaismoradi 2013). Placing greater importance on code frequency may remove context in this study with such few participants. For this reason, I have chosen to thematic analysis which embraces subjectivity, encouraging the use of contextual knowledge. Although this does bring to question the research reliability, it provides space to uncover covert themes within the data (Guest et al, 2012).
Considering my ethical approach on this study, reflecting on bias, positionality and approach, content analysis is a more appropriate method. However, to address the research question, ‘Can personal artefacts increase student engagement to digital software?’, the implicit data requires deep investigation – particularly in a educational setting where students may not overtly express their feelings. Utilising reflexive thematic analysis, I have taken an inductive, semantic, (critical) realist approach. (University of Auckland, 2022) Allowing the participant data to guide code/theme creation whilst using my knowledge of the existing teaching space to deduce context of the data. However, my approach to code generation differs from the reflexive thematic approach.
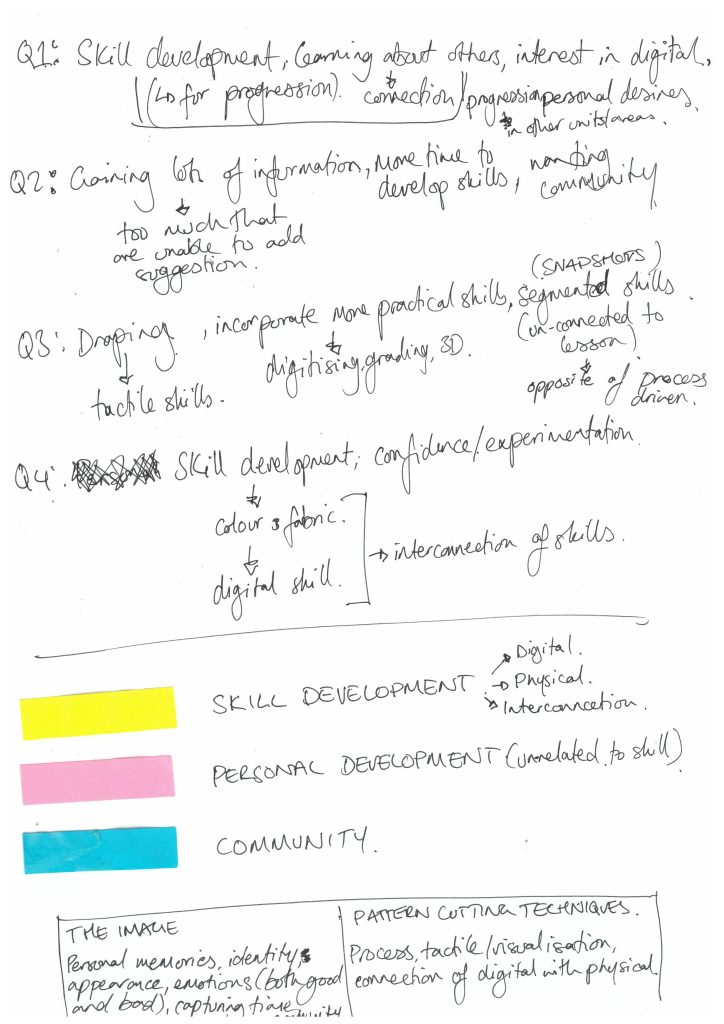
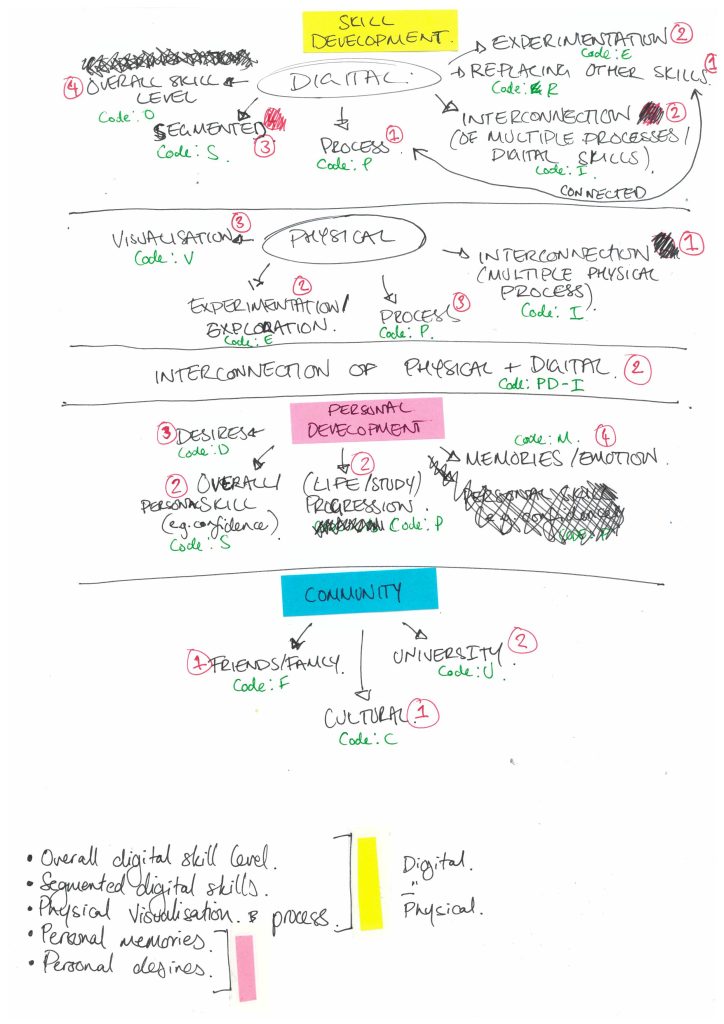
I began with segmenting the data, based on the worksheet structures, reading the data from one section at a time for all three participants. During this process of familiarisation I created rough notes on the data from all three datasets. I would not label this process as code-creation as there were no label repetition. I then began to break down each themes into codes, adding new themes/codes where necessary. This method is more in-line with the applied thematic approach (Guest et al, 2012) Due to the limited data, segmented into even smaller sections, themes quickly became apparent.
From this, I reviewed code frequency within each section. At times codes appeared multiple times within one body of text. For parity, those more able or less able to write at length, each appearance of a code was equated to one. Considering both latent and manifest appearance of codes and code frequency, I began comparing the relationship between codes across each section and followed by the entire dataset to review and refine themes.





Vaismoradi, M., Turunen, H., Bondas, T. (2013) Content analysis and thematic analysis: Implications for conducting a qualitative descriptive study. Nursing & Health Sciences, 15, pp.398–405. https://doi.org/10.1111/nhs.12048 (Accessed 28 December
Krippendorff, K. (2019) Content Analysis: An Introduction to Its Methodology: Fourth Edition Thousand Oaks. SAGE Publications, Inc. Available at: https://doi.org/10.4135/9781071878781 (Accessed 27 December 2023)
Waipapa Taumata Rau The University of Auckland, New Zealand (2022) Understanding TA. Accessed from: https://www.thematicanalysis.net/understanding-ta/ (Accessed 4 January 2023)
Guest, G., MacQueen, K. M. and Namey, E. E. (2012) Applied Thematic Analysis : Thousand Oaks, SAGE Publications, Inc. Available at: https://doi.org/10.4135/9781483384436 (Accessed 27 December 2023)